



1.多模态编程语言大模型的应用:金睛云华检测大模型
金睛云华的AI技术始终紧跟业界前沿,积极引领并推动着整个网络安全领域的发展。在之前的人工智能小模型时代,金睛云华基于监督学习类算法,实现了20多个攻击检测场景的覆盖,并且解决了加密流量检测的业内难题,形成了独特的竞争优势。期间,金睛云华建立了国内网络安全领域最大的人工智能超算平台,并积累了海量的高质量标注数据。进入到人工智能大模型时代,金睛云华基于程序语言大模型、自然语言大模型以及多模态、多场景迁移学习等核心算法支持,在国内率先发布了商用安全大模型——金睛云华“安心大模型「CyberGPT」”,在之前小模型的基础上进一步增强了检测能力,在漏报、误报和检测成本方面获得了从量变到质变的提升。金睛云华对于威胁检测领域检测技术的演进技术路线如下图所示:
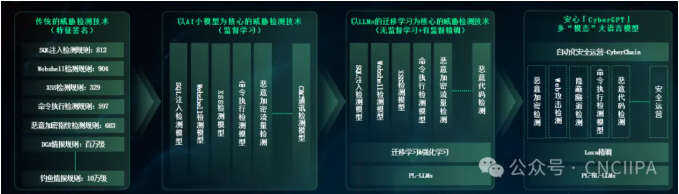
图1 金睛云华威胁检测技术演进
本文后续章节,不考虑自动化安全运营相关的技术,只展开讨论CyberGPT用户恶意流量实时检测相关的技术实践。
2. 检测大模型的技术原理
多模态编程语言模型PL-LLMs是编程语言(PL)和自然语言(NL)的双峰预训练模型,模型支持Python, Java, JavaScript, PHP, Ruby, Go等主流编程语言的预训练,对于未知漏洞检测和恶意加密流量检测这种包含编程语言格式和自然语言格式的数据流具有很高的适应性。为此,金睛云华的多模态编程语言大模型进行了4阶段的技术验证,包括:
1.对于web攻击和未知漏洞检测,金睛云华利用在AI小模型阶段积累的基于语义分析的监督学习小模型,以编程语言大模型为底座进行精调,能够无缝地对接所有AI小模型的训练语料,实现把SQL注入语义分析模型、XSS语义分析模型、WebShell语义分析模型、Windows系统命令执行模型、Linux Shell命令执行模型、PHP代码执行模型、JSP代码执行模型、Java代码执行模型、ASP代码执行模型、Struts代码执行模型、目录遍历/穿越模型、XML外部实体注入模型等AI小模型的训练语料在一个编程语言大模型上进行精调( fine-tuning),构建一个具备多分类效果的检测大模型;
2.对于恶意加密流量的检测,在AI小模型阶段,我们提取数据流、数据会话、应用层TLS/SSL协议特征、DNS/HTTP背景流特征等多层次检测特征进行训练。针对编程语言大模型适应自然语言和编程语言的特性,我们将恶意加密流量会话的AI小模型统计特征和会话载荷文本特征相结合,抽取结合后的特征,在一个编程语言大模型上进行精调( fine-tuning),构建一个具备多分类效果的检测大模型,输出每个加密会话是否为恶意流量,且输出其攻击工具的类别(黑客工具名称)。
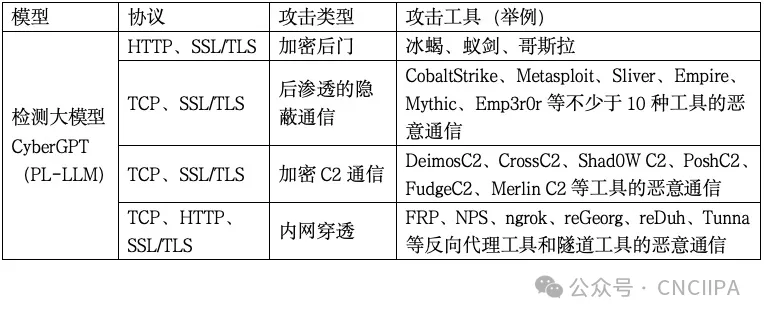
3.在前2个阶段技术验证成功的基础上,将web攻击和未知漏洞检测、恶意加密流量检测的所有样本进行合并,构建一个统一的多模态编程语言大模型训练数据集,以亿级参数的多模态编程语言大模型为底座进行精调,训练出一个能在TCP、UDP、HTTP、SSL、TLS协议上检测不同攻击的检测大模型,如下表所示:
4.多模态大模型支持LoRa(Low-Rank Adaptation)微调技术,Lora微调是一种基于低秩适应的微调技术,它通过在LLM的权重矩阵上应用分解低秩矩阵,将模型的参数量大幅减少,从而降低计算复杂度和内存需求。使得LoRa在保持模型能力的同时,能够在有限的GPU/CPU计算资源下进行高效的微调,从而使得检测大模型相比AI小模型具有显著的优势,包括:
(1)使得我们模型可以分成部署前训练和部署后增量训练2个阶段。在部署前,我们采用LoRa微调从PL(编程语言)语言大模型开始,在百万级到千万级的攻击样本规模下利用AI-GPU集群训练一个可靠的上线模型;在部署后,模型能够在真实流量下基于大量白流量,在有限的计算资源下(例如支持最小1块GPU)在几个小时内完成增量学习,在部署的用户侧不断降低模型的误报率。
(2)冻结了预训练模型的权重,并将低秩分解矩阵注入到transformer的每一层,减少了训练参数量。在将恶意网络流量特征注入大模型的同时,保留了大模型原有能力(即对基于编程语言攻击载荷的检测能力,例如各种脚本语言的webshell上传、PHP代码执行、JSP代码执行、Java代码执行、ASP代码执行、Struts代码执行、XML外部实体(XXE)注入等攻击载荷),方便后续扩展到其他不同的恶意攻击流量检测。
(3)快速适应特定的攻击检测任务任务:在发现0day攻击或未知、在野漏洞、新型木马变种时,LoRa微调可以将通用的预训练模型转化为适应特定攻击样本训练和检测的模型。通过微调,可以将预训练模型的知识和特征迁移到新的攻击检测模型训练任务中,从而更好和更快地适应未知攻击、未知漏洞等检测任务的需求。
(4)Lora训练算法由于广泛使用,主流的大模型训练算法和平台都支持Lora微调的快速部署,具备完整流程的各种功能,使得比较容易采用一些训练和推理(检测)加速技术,例如:模型FP16混合精度训练加速技术、支持FastTransformer训练加速算法、INT8/INT4模型量化算法加速推理、模型词表裁剪或扩充、模型裁剪(裁剪每个transformer模块的大小,研究表明transformer中的注意力头"attention heads"并不是同等重要,移除不重要的注意力头并不会显著降低模型性能。找到并移除每个transformer中“不重要”的注意力头和全连接层神经元,从而在减小模型体积的同时把对模型性能的影响尽可能降到最低。)等模型优化技术,更好适应超大规模网络跨域恶意流量的训练和检测性能要求。
检测大模型训练和精调的技术原理如下图所示:

图2 检测大模型精调技术原理
检测大模型使用Lora微调技术使用AI-GPU集群进行训练,训练的关键参数包裹epoch、batch_size和最大输入token长度等。检测大模型相对小模型训练,对迭代轮次和最大输入token长度的要求较高,对正负样本的均衡性,每类样本的数据比例不是很敏感,batch_size的大小取决于AI-GPU集群的规模,训练过程如下图所示:

图3 集群训练检测大模型过程图
3. 检测大模型对恶意加密流量的训练和检测实践:以Cobalt Strike为例
CobaltStrike是红队使用最广泛的渗透工具,集成了涉及攻击全流程的不同攻击组件,其核心的攻击过程是下发木马和进行C2控制。由于该工具被攻击者广泛使用,所以其通信流量通常被加密传输以逃避安全设备的检测。
为充分发挥检测大模型对不同类型的数据具有良好适应性的特点,也为了尽可能模拟攻击者主要的攻击方式,我们在捕获Cobalt Strike的加密通信流量提取大模型训练样本的过程中,从如下几个维度捕获覆盖主要攻击方式、工具主流版本的攻击数据,包括:
1.Cobalt Strike主流版本,支持Cobalt Strike3.11,CobaltStrike3.14,CobaltStrike4.0,cobaltstrike4.1,cobaltstrike4.4,cobaltstrike4.5,cobaltstrike4.8等版本;
2.受害主机操作系统,支持主流windows操作系统,例如:Windows 7、 Windows 8、 Windows 10、Windows 11、 Windows Server 2008、 Windows Server 201、 Windows Server 2016、 Windows Server 2019等版本;
3.外联的攻击者主控端操作系统:支持centos, debian, ubuntu, windows等
4.中间件Java版本:支持JDK8、JDK11和JDK17等主流版本;
5.木马载荷下发支持Stager、Stageless方式
6.下发木马可执行文件支持x86, x64等
7.木马植入后进行C2的每次连接是从十余种控制命令中随机选择,例如:"ipconfig", "net user", "dir", "whoami /all", "query user", "net localgroup", "net use", "net share", "tasklist /svc", "netstat -ano", "tasklist", "systeminfo"等
8.加密方式和配置:使用多种profile配置文件覆盖默认证书自定义证书情况,例如:gmail.profile, googledrive_getonly.profile, meterpreter.profile等十余种不同配置。
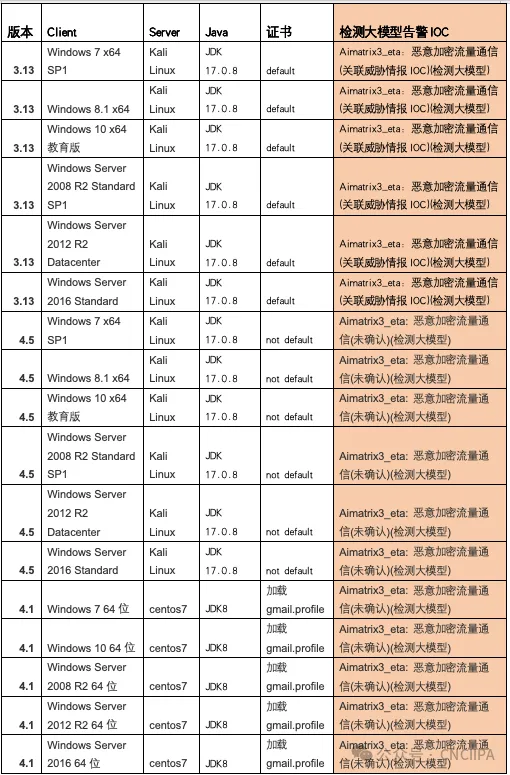
对按照以上方式构建的加密流量攻击模拟数据,在检测大模型训练后,交叉验证准确率可达到98%以上。限于篇幅,本文只节选一小部分攻击模拟数据在金睛云华检测大模型产品上测试的告警IOC的情况,如下表所示:
4. 总结
在本文中,我们探讨了金睛云华如何逐步选择和精调多模态编程语言模型为底座的检测大模型,从而用一个模型实现web攻击、未知漏洞、典型黑客工具的恶意加密流量检测。而且充分利用大模型的Lora微调技术,能够在1-2块GPU上实现快速的检测、自适应的用户白流量增量学习,不断降低误报和提升对攻击的检出率。
同时,为充分利用模型对不同攻击在不同版本、环境、配置和攻击行为下都能够有效精调的特点,对以CobaltStrike为代表的主流黑客工具进行深度攻击模拟和检测挖掘,提高模型的泛化能力。最后,积极应用最新的大模型加速技术,例如模型FP16混合精度训练加速技术、支持FastTransformer训练加速算法、INT8/INT4模型量化算法加速推理、模型词表裁剪和模型裁剪(裁剪每个transformer模块的大小)等技术,实现在真实用户环境下2-3Gbps的高速检测性能,从而具备大模型在流量检测领域的落地能力,为我们后续在恶意流量检测领域研究、验证和实践检测大模型打下坚实基础。


 地 址:北京市海淀区世纪金源商务中心 607室
地 址:北京市海淀区世纪金源商务中心 607室 13810321968(微信同号)
13810321968(微信同号)